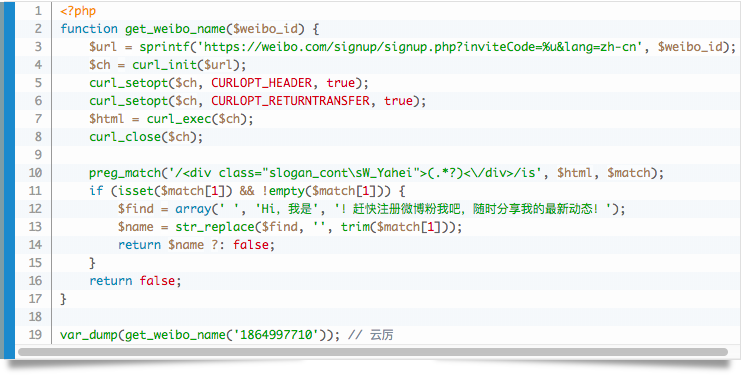
[font=微软雅黑][size=4][b][color=SeaGreen]常规篇:[/b][/size][/font]
首先,用ps查看进程,方法如下:
[code]ps -ef[/code]
……
smx 1822 1 0 11:38 ? 00:00:49 gnome-terminal
smx 1823 1822 0 11:38 ? 00:00:00 gnome-pty-helper
smx 1824 1822 0 11:38 pts/0 00:00:02 bash
smx 1827 1 4 11:38 ? 00:26:28 /usr/lib/firefox-3.6.18/firefox-bin
smx 1857 1822 0 11:38 pts/1 00:00:00 bash
smx 1880 1619 0 11:38 ? 00:00:00 update-notifier
……
smx 11946 1824 0 21:41 pts/0 00:00:00 ps -ef
或者:
[code]ps -aux[/code]
……
smx 1822 0.1 0.8 58484 18152 ? Sl 11:38 0:49 gnome-terminal
smx 1823 0.0 0.0 1988 712 ? S 11:38 0:00 gnome-pty-helper
smx 1824 0.0 0.1 6820 3776 pts/0 Ss 11:38 0:02 bash
smx 1827 4.3 5.8 398196 119568 ? Sl 11:38 26:13 /usr/lib/firefox-3.6.18/firefox-bin
smx 1857 0.0 0.1 6688 3644 pts/1 Ss 11:38 0:00 bash
smx 1880 0.0 0.6 41536 12620 ? S 11:38 0:00 update-notifier
……
smx 11953 0.0 0.0 2716 1064 pts/0 R+ 21:42 0:00 ps -aux
此时如果我想杀了火狐的进程就在终端输入:
[code]kill -s 9 1827[/code]
其中-s 9 制定了传递给进程的信号是9,即强制、尽快终止进程。各个终止信号及其作用见附录。
1827则是上面ps查到的火狐的PID。
简单吧,但有个问题,进程少了则无所谓,进程多了,就会觉得痛苦了,
无论是ps -ef 还是ps -aux,每次都要在一大串进程信息里面查找到要杀的进程,看的眼都花了。
[font=微软雅黑][size=4][b][color=SeaGreen]改进1:[/b][/size][/font]
把ps的查询结果通过管道给grep查找包含特定字符串的进程。管道符“|”用来隔开两个命令,管道符左边命令的输出会作为管道符右边命令的输入。
[code]ps -ef | grep firefox[/code]
smx 1827 1 4 11:38 ? 00:27:33 /usr/lib/firefox-3.6.18/firefox-bin
smx 12029 1824 0 21:54 pts/0 00:00:00 grep --color=auto firefox
这次就清爽了。然后就是
[code]kill -s 9 1827[/code]
还是嫌打字多?
[font=微软雅黑][size=4][b][color=SeaGreen]改进2 ———使用pgrep:[/b][/size][/font]
一看到pgrep首先会想到什么?没错,grep!pgrep的p表明了这个命令是专门用于进程查询的grep。
[code]pgrep firefox[/code]
1827
看到了什么?没错火狐的PID,接下来又要打字了:
[code]kill -s 9 1827[/code]
[font=微软雅黑][size=4][b][color=SeaGreen]改进3 ——使用pidof:[/b][/size][/font]
看到pidof想到啥?没错pid of xx,字面翻译过来就是 xx的PID。
[code]pidof firefox-bin[/code]
1827
和pgrep相比稍显不足的是,pidof必须给出进程的全名。然后就是老生常谈:
[code]kill -s 9 1827[/code]
无论使用ps 然后慢慢查找进程PID
还是用grep查找包含相应字符串的进程,
亦或者用pgrep直接查找包含相应字符串的进程PID,然后手动输入给kill杀掉,都稍显麻烦。
有没有更方便的方法?有!
[font=微软雅黑][size=4][b][color=SeaGreen]改进4:[/b][/size][/font]
[code]ps -ef | grep firefox | grep -v grep | cut -c 9-15 | xargs kill -s 9[/code]
说明:
“grep firefox”的输出结果是,所有含有关键字“firefox”的进程。
“grep -v grep”是在列出的进程中去除含有关键字“grep”的进程。
“cut -c 9-15”是截取输入行的第9个字符到第15个字符,而这正好是进程号PID。
“xargs kill -s 9”中的xargs命令是用来把前面命令的输出结果(PID)作为“kill -s 9”命令的参数,并执行该命令。“kill -s 9”会强行杀掉指定进程。
难道你不想抱怨点什么?没错太长了
[font=微软雅黑][size=4][b][color=SeaGreen]改进5:[/b][/size][/font]
知道pgrep和pidof两个命令,干嘛还要打那么长一串!
[code]pgrep firefox | xargs kill -s 9[/code]
[font=微软雅黑][size=4][b][color=SeaGreen]改进6:[/b][/size][/font]
[code]ps -ef | grep firefox | awk '{print $2}' | xargs kill -9[/code]
kill: No such process
有一个比较郁闷的地方,进程已经正确找到并且终止了,但是执行完却提示找不到进程。
其中awk '{print $2}' 的作用就是打印(print)出第二列的内容。根据常规篇,可以知道ps输出的第二列正好是PID。就把进程相应的PID通过xargs传递给kill作参数,杀掉对应的进程。
[font=微软雅黑][size=4][b][color=SeaGreen]改进7:[/b][/size][/font]
难道每次都要调用xargs把PID传递给kill?答案是否定的:
[code]kill -s 9 `ps -aux | grep firefox | awk '{print $2}'`[/code]
[font=微软雅黑][size=4][b][color=SeaGreen]改进8:[/b][/size][/font]
没错,命令依然有点长,换成pgrep。
[code]kill -s 9 `pgrep firefox`[/code]
[font=微软雅黑][size=4][b][color=SeaGreen]改进9——pkill:[/b][/size][/font]
看到pkill想到了什么?没错pgrep和kill!pkill=pgrep+kill。
[code]pkill -9 firefox[/code]
说明:"-9" 即发送的信号是9,pkill与kill在这点的差别是:pkill无须 “s”,终止信号等级直接跟在 “-“ 后面。之前我一直以为是 "-s 9",结果每次运行都无法终止进程。
[font=微软雅黑][size=4][b][color=SeaGreen]改进10——killall:[/b][/size][/font]
killall和pkill是相似的,不过如果给出的进程名不完整,killall会报错。pkill或者pgrep只要给出进程名的一部分就可以终止进程。
[code]killall -9 firefox[/code]
附录:各种信号及其用途
[table=100%]
| Signal |
Description |
Signal number on Linux x86[1] |
| SIGABRT |
Process aborted |
6 |
| SIGALRM |
Signal raised by alarm |
14 |
| SIGBUS |
Bus error: "access to undefined portion of memory object" |
7 |
| SIGCHLD |
Child process terminated, stopped (or continued*) |
17 |
| SIGCONT |
Continue if stopped |
18 |
| SIGFPE |
Floating point exception: "erroneous arithmetic operation" |
8 |
| SIGHUP |
Hangup |
1 |
| SIGILL |
Illegal instruction |
4 |
| SIGINT |
Interrupt |
2 |
| SIGKILL |
Kill (terminate immediately) |
9 |
| SIGPIPE |
Write to pipe with no one reading |
13 |
| SIGQUIT |
Quit and dump core |
3 |
| SIGSEGV |
Segmentation violation |
11 |
| SIGSTOP |
Stop executing temporarily |
19 |
| SIGTERM |
Termination (request to terminate) |
15 |
| SIGTSTP |
Terminal stop signal |
20 |
| SIGTTIN |
Background process attempting to read from tty ("in") |
21
|
| SIGTTOU |
Background process attempting to write to tty ("out") |
22
|
| SIGUSR1 |
User-defined 1 |
10
|
| SIGUSR2 |
User-defined 2 |
12
|
| SIGPOLL |
Pollable event |
29
|
| SIGPROF |
Profiling timer expired |
27
|
| SIGSYS |
Bad syscall |
31
|
| SIGTRAP |
Trace/breakpoint trap |
5
|
| SIGURG |
Urgent data available on socket |
23
|
| SIGVTALRM |
Signal raised by timer counting virtual time: "virtual timer expired" |
26
|
| SIGXCPU |
CPU time limit exceeded |
24
|
| SIGXFSZ |
File size limit exceeded |
25
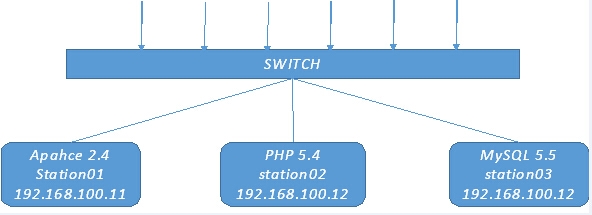
考虑到复杂的应用环境,我们将Apache/PHP/MySQL三种服务独立配置不同主机
我们知道Apache与PHP有三种工作模式:
第一种现在用得很少了,性能差;对于动态页面全部由Apache进程启用PHP解释器,然后再释放
第二种需要到本地磁盘加载Modules模块,性能比第一种好,但还是会有很多消耗资源
第三种PHP是一个独立应用,通过网络套接字接口,接收Apache进程传过来的请求,所有PHP进程都由PHP自身管理
在PHP5.4以前,如果PHP需要连接mysql需要MySQL头文件等,
在php5.4以后就不需要了,直接使用
--with-mysql=mysqlnd --with-pdo-mysql=mysqlnd --with-mysqli=mysqlnd
由于Apache并不处理动态页面,所以前端用户请求的PHP页面需要转发到PHP服务器上,这里就需要对Apache做反向代理设置
当然了,我们在这里最好启用虚拟主机功能,这样方便管理。
编译安装Apache2.4.4
准备软件包:
apr-1.4.6.tar.gz
apr-util-1.4.1.tar.gz
httpd-2.4.4.tar.bz2
pcre-8.32.tar.gz
[root@station01 ~]# tar xf apr-1.4.6.tar.gz
[root@station01 ~]# cd apr-1.4.6
[root@station01 apr-1.4.6]# ./configure --prefix=/usr/local/apr
[root@station01 apr-1.4.6]# make &&make install
[root@station01 apr-1.4.6]# cd ..
[root@station01 ~]# tar xf apr-util-1.4.1.tar.gz
[root@station01 ~]# cd apr-util-1.4.1
[root@station01 apr-util-1.4.1]# ./configure --prefix=/usr/local/apr-util --with-apr=/usr/local/apr
[root@station01 apr-util-1.4.1]# make &&make install
[root@station01 apr-util-1.4.1]# cd
[root@station01 ~]# tar xf httpd-2.4.4.tar.bz2
[root@station01 ~]# cd httpd-2.4.4
[root@station01 httpd-2.4.4]# ./configure --prefix=/usr/local/apache --sysconfdir=/etc/httpd --enable-so --enable-ssl --enable-cgi --enable-rewrite --with-zlib --with-pcre=/usr/local/pcre --with-apr=/usr/local/apr --with-apr-util=/usr/local/apr-util --enable-modules=most --enable-mpms-shared=all --with-mpm=event
[root@station01 httpd-2.4.4]# make &&make install
[root@station01 httpd-2.4.4]# cp build/rpm/httpd.init /etc/init.d/httpd
[root@station01 httpd-2.4.4]# vim /etc/init.d/httpd
httpd=${HTTPD-/usr/local/apache/bin/httpd}
pidfile=${PIDFILE-/usr/local/apache/logs/${prog}.pid}
lockfile=${LOCKFILE-/var/lock/subsys/${prog}}
RETVAL=0
CONFFILE=/etc/httpd/httpd.conf
[root@station01 httpd-2.4.4]# chkconfig --add httpd
[root@station01 httpd-2.4.4]# chkconfig httpd on
[root@station01 httpd-2.4.4]# service httpd start
编译安装PHP5.4
准备软件包:
libmcrypt-2.5.7-5.el5.i386.rpm
libmcrypt-devel-2.5.7-5.el5.i386.rpm
php-5.4.13.tar.bz2
[root@station02 ~]# rpm -ivh *.rpm
[root@station02 ~]# tar xf php-5.4.13.tar.bz2
[root@station02 ~]# cd php-5.4.13
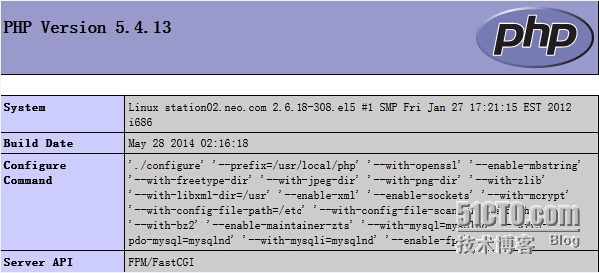
[root@station02 php-5.4.13]# ./configure --prefix=/usr/local/php --with-openssl --enable-mbstring --with-freetype-dir --with-jpeg-dir --with-png-dir --with-zlib --with-libxml-dir=/usr --enable-xml --enable-sockets --with-mcrypt --with-config-file-path=/etc --with-config-file-scan-dir=/etc/php.d --with-bz2 --enable-maintainer-zts --with-mysql=mysqlnd --with-pdo-mysql=mysqlnd --with-mysqli=mysqlnd --enable-fpm
[root@station02 php-5.4.13]# make &&make install
[root@station02 php-5.4.13]# cp php.ini-production /etc/php.ini
[root@station02 php-5.4.13]# cp sapi/fpm/init.d.php-fpm /etc/init.d/php-fpm
[root@station02 php-5.4.13]# chmod +x /etc/init.d/php-fpm
[root@station02 php-5.4.13]# chkconfig --add php-fpm
[root@station02 php-5.4.13]# chkconfig php-fpm on
[root@station02 php-5.4.13]# cd /usr/local/php/
[root@station02 php]# cp etc/php-fpm.conf.default etc/php-fpm.conf
[root@station02 php]# vim etc/php-fpm.conf[/code]
配置fpm的相关选项为你所需要的值,并启用pid文件:
[code]pm.max_children = 50
pm.start_servers = 5
pm.min_spare_servers = 2
pm.max_spare_servers = 8
pid = /usr/local/php/var/run/php-fpm.pid
[root@station02 php]# service php-fpm start[/code]
检查php-fpm是否正常
[code][root@station02 php]# netstat -tunlp |grep 9000
[root@station02 php]# ps -ef |grep php-fpm
二进制配置MySQL
[root@station03 ~]# tar xf mysql-5.5.28-linux2.6-i686.tar.gz -C /usr/local/
[root@station03 ~]# cd /usr/local/
[root@station03 local]# groupadd -g 3306 mysql
[root@station03 local]# useradd -g mysql -u 3306 mysql -s /sbin/nologin -M
[root@station03 local]# ln -s mysql-5.5.28-linux2.6-i686/ mysql
[root@station03 local]# cd mysql
[root@station03 mysql]# chown -R mysql.root .
[root@station03 mysql]# chown -R mysql.mysql data/
[root@station03 mysql]# scripts/mysql_install_db --datadir=/usr/local/mysql/data/ --user=mysql
[root@station03 mysql]# cp support-files/mysql.server /etc/init.d/mysqld
[root@station03 mysql]# chmod +x /etc/init.d/mysqld
[root@station03 mysql]# chkconfig --add mysqld
[root@station03 mysql]# chkconfig mysqld on
[root@station03 mysql]# cp support-files/my-large.cnf /etc/my.cnf
[root@station03 mysql]# vim /etc/my.cnf
#如果data目录更改,则需要在mysqld段中注明
[root@station03 mysql]# service mysqld start
[root@station03 mysql]# vim /etc/profile.d/mysqld.sh
export PATH=$PATH:/usr/local/mysql/bin
[root@station03 mysql]# . /etc/profile.d/mysqld.sh
[root@station03 ~]# mysql
mysql> update user set password=password('asdasd') where user='root';
mysql> flush privileges;
Apache与PHP整合工作
[root@station01 ~]# vim /etc/httpd/httpd.conf[/code]
[code]#DocumentRoot "/usr/local/apache/htdocs"
DirectoryIndex index.html index.php
AddType application/x-httpd-php .php
AddType application/x-httpd-php-source .phps
Include /etc/httpd/extra/httpd-vhosts.conf
LoadModule proxy_fcgi_module modules/mod_proxy_fcgi.so
LoadModule proxy_module modules/mod_proxy.so
[root@station01 ~]# vim /etc/httpd/extra/httpd-vhosts.conf
<VirtualHost *:80>
DocumentRoot "/web/html"
ServerName "www.neo.com"
ErrorLog "logs/www.neo.com_error_log"
CustomLog "logs/www.neo.com_access_log" combined
<Directory "/web/html">
Options None
Require all granted
</Directory>
ProxyRequests Off
ProxyPassMatch ^/(.*)\.php$ fcgi://192.168.100.12:9000/web/html/$1.php
</VirtualHost>[/code]
[code][root@station01 ~]# mkdir /web/html -p
[root@station02 ~]# mkdir /web/html -p
[root@station01 ~]# vim /web/html/index.php
<?php
phpinfo();
浏览器访问http://192.168.100.11/index.php
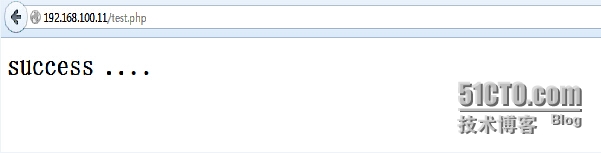
验证PHP是否能连上MySQL
<?php
$link=mysql_connect('192.168.100.13','root','asdasd');
if(!$link)
echo "<h1>connect failed !!!!</h1> ";
else
echo "<h1>success ....</h1>";
mysql_close();
转载自:http://junwang.blog.51cto.com/5050337/1422899
为了以后能开发PHP扩展,就一定要了解PHP的执行顺序。这篇文章就是为C开发PHP扩展做铺垫。
Web环境我们假设为Apache!
在编译PHP的时候,为了能够让Apache支持PHP,Apache 需要加载 mod_php5.so 这个模块,
在URL访问PHP文件的时候,就会转给 mod_php5.so 模块来处理。这个就是我们常说的SAPI(Server Application Programming Interface)
SAPI其实是一个统称,其下有 ISAPI,CLI SAPI,CGI等。
有了它,就可以很容易的跟其他东西交互,比如APACHE,IIS,CGI等。
Apache启动后会将mod_pho5.so模块的hook handler注册进来,当Apache检测到访问的url是一个php文件时,这时候就会把控制权交给SAPI。
进入到SAPI后,首先会执行sapi/apache/mod_php5.c 文件的php_init_handler函数,这里摘录一段代码:
static void php_init_handler(server_rec *s, pool *p)
{
register_cleanup(p, NULL, (void (*)(void *))apache_php_module_shutdown_wrapper, (void (*)(void *))php_module_shutdown_for_exec);
if (!apache_php_initialized) {
apache_php_initialized = 1;
#ifdef ZTS
tsrm_startup(1, 1, 0, NULL);
#endif
sapi_startup(&apache_sapi_module);
php_apache_startup(&apache_sapi_module);
}
#if MODULE_MAGIC_NUMBER >= 19980527
{
TSRMLS_FETCH();
if (PG(expose_php)) {
ap_add_version_component("PHP/" PHP_VERSION);
}
}
#endif
}
该函数主要调用两个函数:
sapi_startup(&apache_sapi_module);
php_apache_startup(&apache_sapi_module);
SAPI_API void sapi_startup(sapi_module_struct *sf)
{
sf->ini_entries = NULL;
sapi_module = *sf;
.................
sapi_globals_ctor(&sapi_globals);
................
virtual_cwd_startup(); /* Could use shutdown to free the main cwd but it would just slow it down for CGI */
.................
reentrancy_startup();
}
sapi_startup创建一个 sapi_globals_struct结构体。sapi_globals_struct保存了Apache请求的基本信息,如服务器信息,Header,编码等。
sapi_startup执行完毕后再执行php_apache_startup。
static int php_apache_startup(sapi_module_struct *sapi_module)
{
if (php_module_startup(sapi_module, &apache_module_entry, 1) == FAILURE) {
return FAILURE;
} else {
return SUCCESS;
}
}
php_module_startup 内容太多,这里介绍一下大致的作用:
1. 初始化zend_utility_functions 结构.这个结构是设置zend的函数指针,比如错误处理函数,输出函数,流操作函数等
2. 设置环境变量
3. 加载php.ini配置
4. 加载php内置扩展
5. 写日志
6. 注册php内部函数集
7. 调用 php_ini_register_extensions,加载所有外部扩展
8. 开启所有扩展
9. 一些清理操作
重点说一下 3,4,7,8
加载php.ini配置
if (php_init_config(TSRMLS_C) == FAILURE) {
return FAILURE;
}
php_init_config函数会在这里检查所有php.ini配置,并且找到所有加载的模块,添加到php_extension_lists结构中。
加载php内置扩展
调用 zend_register_standard_ini_entries加载所有php的内置扩展,如array,mysql等。
调用 php_ini_register_extensions,加载所有外部扩展
main/php_ini.c
void php_ini_register_extensions(TSRMLS_D)
{
zend_llist_apply(&extension_lists.engine, php_load_zend_extension_cb TSRMLS_CC);
zend_llist_apply(&extension_lists.functions, php_load_php_extension_cb TSRMLS_CC);
zend_llist_destroy(&extension_lists.engine);
zend_llist_destroy(&extension_lists.functions);
}
zend_llist_apply函数遍历extension_lists 执行会掉函数 php_load_php_extension_cb
static void php_load_zend_extension_cb(void *arg TSRMLS_DC)
{
zend_load_extension(*((char **) arg));
}[/code]
该函数最后调用
[code]if ((module_entry = zend_register_module_ex(module_entry TSRMLS_CC)) == NULL) {
DL_UNLOAD(handle);
return FAILURE;
}
将扩展信息放到 Hash表module_registry中,Zend/zend_API.c
if (zend_hash_add(&module_registry, lcname, name_len+1, (void *)module, sizeof(zend_module_entry), (void**)&module_ptr)==FAILURE) {
zend_error(E_CORE_WARNING, "Module '%s' already loaded", module->name);
efree(lcname);
return NULL;
}
最后,zend_startup_modules(TSRMLS_C);
对模块进行排序,并检测是否注册到module_registry HASH表里。
zend_startup_extensions(); 执行extension->startup(extension);启动扩展。
转载自:http://www.searchtb.com/2012/07/php-execution-flow.html
传统上,软件和网络是两个不同的领域,很少有交集;软件开发主要针对单机环境,网络则主要研究系统之间的通信。
互联网的兴起,使得这两个领域开始融合,即 "互联网软件",比网站、网络游戏、各种非单机版APP等,
这种"互联网软件"采用客户端/服务器(C/S)模式,建立在分布式体系上,通过互联网通信,具有高延时(high latency)、高并发等特点。
那么如何开发在互联网环境中使用的软件呢?
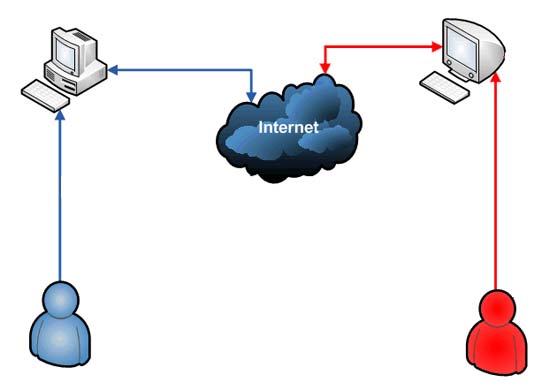
RESTful架构,就是目前非常流行的一种互联网软件架构。
它结构清晰、符合标准、易于理解、扩展方便,所以正得到越来越多网站的采用。
但是,到底什么是RESTful架构,并不是一个容易说清楚的问题。下面,我就谈谈我理解的RESTful架构。
一、起源
REST 这个词,是Roy Thomas Fielding在他2000年的博士论文中提出的。

Fielding是一个非常重要的人,他是HTTP协议(1.0版和1.1版)的主要设计者、Apache服务器软件的作者之一、Apache基金会的第一任主席。
所以,他的这篇论文一经发表,就引起了关注,并且立即对互联网开发产生了深远的影响。
他这样介绍论文的写作目的:
本文研究计算机科学两大前沿----软件和网络----的交叉点。长期以来,软件研究主要关注软件设计的分类、设计方法的演化,很少客观地评估不同的设计选择对系统行为的影响。而相反地,网络研究主要关注系统之间通信行为的细节、如何改进特定通信机制的表现,常常忽视了一个事实,那就是改变应用程序的互动风格比改变互动协议,对整体表现有更大的影响。我这篇文章的写作目的,就是想在符合架构原理的前提下,理解和评估以网络为基础的应用软件的架构设计,得到一个功能强、性能好、适宜通信的架构。
(This dissertation explores a junction on the frontiers of two research disciplines in computer science: software and networking. Software research has long been concerned with the categorization of software designs and the development of design methodologies, but has rarely been able to objectively evaluate the impact of various design choices on system behavior. Networking research, in contrast, is focused on the details of generic communication behavior between systems and improving the performance of particular communication techniques, often ignoring the fact that changing the interaction style of an application can have more impact on performance than the communication protocols used for that interaction. My work is motivated by the desire to understand and evaluate the architectural design of network-based application software through principled use of architectural constraints, thereby obtaining the functional, performance, and social properties desired of an architecture. )
二、名称
Fielding将他对互联网软件的架构原则,定名为REST,即Representational State Transfer的缩写。我对这个词组的翻译是"表现层状态转化"。
如果一个架构符合REST原则,就称它为RESTful架构。
要理解RESTful架构,最好的方法就是去理解Representational State Transfer这个词组到底是什么意思,它的每一个词代表了什么涵义。
如果你把这个名称搞懂了,也就不难体会REST是一种什么样的设计。
三、资源(Resources)
REST的名称"表现层状态转化"中,省略了主语。"表现层"其实指的是"资源"(Resources)的"表现层"。
所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文本、一张图片、一首歌曲、一种服务,总之就是一个具体的实在。
你可以用一个URI(统一资源定位符)指向它,每种资源对应一个特定的URI。
要获取这个资源,访问它的URI就可以,因此URI就成了每一个资源的地址或独一无二的识别符。
所谓"上网",就是与互联网上一系列的"资源"互动,调用它的URI。
四、表现层(Representation)
"资源"是一种信息实体,它可以有多种外在表现形式。我们把"资源"具体呈现出来的形式,叫做它的"表现层"(Representation)。
比如,文本可以用txt格式表现,也可以用HTML格式、XML格式、JSON格式表现,甚至可以采用二进制格式;图片可以用JPG格式表现,也可以用PNG格式表现。
URI只代表资源的实体,不代表它的形式。严格地说,有些网址最后的".html"后缀名是不必要的,因为这个后缀名表示格式,属于"表现层"范畴,而URI应该只代表"资源"的位置。它的具体表现形式,应该在HTTP请求的头信息中用Accept和Content-Type字段指定,这两个字段才是对"表现层"的描述。
五、状态转化(State Transfer)
访问一个网站,就代表了客户端和服务器的一个互动过程。在这个过程中,势必涉及到数据和状态的变化。
互联网通信协议HTTP协议,是一个无状态协议。这意味着,所有的状态都保存在服务器端。因此,如果客户端想要操作服务器,必须通过某种手段,让服务器端发生"状态转化"(State Transfer)。而这种转化是建立在表现层之上的,所以就是"表现层状态转化"。
客户端用到的手段,只能是HTTP协议。
具体来说,就是HTTP协议里面,四个表示操作方式的动词:GET、POST、PUT、DELETE。
它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
六、综述
综合上面的解释,我们总结一下什么是RESTful架构:
- 每一个URI代表一种资源;
- 客户端和服务器之间,传递这种资源的某种表现层;
- 客户端通过四个HTTP动词,对服务器端资源进行操作,实现"表现层状态转化"。
七、误区
RESTful架构有一些典型的设计误区。
最常见的一种设计错误,就是URI包含动词。因为"资源"表示一种实体,所以应该是名词,URI不应该有动词,动词应该放在HTTP协议中。
举例来说,某个URI是/posts/show/1,其中show是动词,这个URI就设计不理想,正确的写法应该是/posts/1,然后用GET方法表示show。
如果某些动作是HTTP动词表示不了的,你就应该把动作做成一种资源。比如网上汇款,从账户1向账户2汇款500元,错误的URI是:
POST /accounts/1/transfer/500/to/2
正确的写法是把动词transfer改成名词transaction,资源不能是动词,但是可以是一种服务:
POST /transaction HTTP/1.1
Host: 127.0.0.1
from=1&to=2&amount=500.00
另一个设计误区,就是在URI中加入版本号:
http://www.example.com/app/1.0/foo
http://www.example.com/app/1.1/foo
http://www.example.com/app/2.0/foo
因为不同的版本,可以理解成同一种资源的不同表现形式,所以应该采用同一个URI。
版本号可以在HTTP请求头信息的Accept字段中进行区分
Accept: vnd.example-com.foo+json; version=1.0
Accept: vnd.example-com.foo+json; version=1.1
Accept: vnd.example-com.foo+json; version=2.0
1、函数的任意数目的参数
你可能知道PHP允许你定义一个默认参数的函数。但你可能并不知道PHP还允许你定义一个完全任意的参数的函数
// 两个默认参数的函数
function foo($arg1 = '', $arg2 = '') {
echo "arg1: $arg1\n";
echo "arg2: $arg2\n";
}
foo('hello','world');
/* 输出:
arg1: hello
arg2: world
*/
foo();
/* 输出:
arg1:
arg2:
*/
现在我们来看一看一个不定参数的函数,其使用到了func_get_args方法:
// 是的,形参列表为空
function foo() {
// 取得所有的传入参数的数组
$args = func_get_args();
foreach ($args as $k => $v) {
echo "arg".($k+1).": $v\n";
}
}
foo();
/* 什么也不会输出 */
foo('hello');
/* 输出
arg1: hello
*/
foo('hello', 'world', 'again');
/* 输出
arg1: hello
arg2: world
arg3: again
*/
2、查找与匹配文件
很多PHP的函数都有一个比较长的自解释的函数名,
但是,当你看到glob的时候,你可能并不知道这个函数是用来干什么的,除非你对它已经很熟悉了。
你可以认为这个函数就好scandir一样,其可以用来查找文件。
// 取得所有后缀为.jpg 的图片文件
$files = glob('*.jpg');
print_r($files);
/* 输出:
Array
(
[0] => phptest.jpg
[1] => pi.jpg
[2] => post_output.jpg
[3] => test.jpg
)
*/[/code]
你还可以查找多种后缀名
[code]// 取PHP文件和TXT文件
$files = glob('*.{php,txt}', GLOB_BRACE);
print_r($files);
/* 输出:
Array
(
[0] => phptest.php
[1] => pi.php
[2] => post_output.php
[3] => test.php
[4] => log.txt
[5] => test.txt
)
你还可以加上路径:
$files = glob('../images/a*.jpg');
print_r($files);
/* 输出:
Array
(
[0] => ../images/apple.jpg
[1] => ../images/art.jpg
)
*/
3、看内存使用信息
观察你程序的内存使用能够让你更好的优化你的代码。
PHP 是有垃圾回收机制的,而且有一套很复杂的内存管理机制。你可以知道你的脚本所使用的内存情况。
要知道当前内存使用情况,你可以使用memory_get_usage函数;
想知道使用内存的峰值,你可以调用memory_get_peak_usage函数。
echo "Initial: ".memory_get_usage()." bytes \n";
/* 输出
Initial: 361400 bytes
*/
// 使用内存
for ($i = 0; $i < 100000; $i++) {
$array []= md5($i);
}
// 删除一半的内存
for ($i = 0; $i < 100000; $i++) {
unset($array[$i]);
}
echo "Final: ".memory_get_usage()." bytes \n";
/* prints
Final: 885912 bytes
*/
echo "Peak: ".memory_get_peak_usage()." bytes \n";
/* 输出峰值
Peak: 13687072 bytes
*/
4、CPU使用信息
使用getrusage函数可以让你知道CPU的使用情况。(注意,这个功能在Windows下不可用)
print_r(getrusage());
/* 输出
Array
(
[ru_oublock] => 0
[ru_inblock] => 0
[ru_msgsnd] => 2
[ru_msgrcv] => 3
[ru_maxrss] => 12692
[ru_ixrss] => 764
[ru_idrss] => 3864
[ru_minflt] => 94
[ru_majflt] => 0
[ru_nsignals] => 1
[ru_nvcsw] => 67
[ru_nivcsw] => 4
[ru_nswap] => 0
[ru_utime.tv_usec] => 0
[ru_utime.tv_sec] => 0
[ru_stime.tv_usec] => 6269
[ru_stime.tv_sec] => 0
)
*/
这个结构看上出很晦涩,除非你对CPU很了解。下面一些解释:
- ru_oublock: 块输出操作
- ru_inblock: 块输入操作
- ru_msgsnd: 发送的message
- ru_msgrcv: 收到的message
- ru_maxrss: 最大驻留集大小
- ru_ixrss: 全部共享内存大小
- ru_idrss:全部非共享内存大小
- ru_minflt: 页回收
- ru_majflt: 页失效
- ru_nsignals: 收到的信号
- ru_nvcsw: 主动上下文切换
- ru_nivcsw: 被动上下文切换
- ru_nswap: 交换区
- ru_utime.tv_usec: 用户态时间 (microseconds)
- ru_utime.tv_sec: 用户态时间(seconds)
- ru_stime.tv_usec: 系统内核时间 (microseconds)
- ru_stime.tv_sec: 系统内核时间?(seconds)
要看到你的脚本消耗了多少CPU,我们需要看看“用户态的时间”和“系统内核时间”的值。秒和微秒部分是分别提供的,您可以把微秒值除以100万,并把它添加到秒的值后,可以得到有小数部分的秒数。
// sleep for 3 seconds (non-busy)
sleep(3);
$data = getrusage();
echo "User time: ".($data['ru_utime.tv_sec'] + $data['ru_utime.tv_usec'] / 1000000);
echo "System time: ".($data['ru_stime.tv_sec'] + $data['ru_stime.tv_usec'] / 1000000);
/* 输出
User time: 0.011552
System time: 0
*/
sleep是不占用系统时间的,我们可以来看下面的一个例子:
// loop 10 million times (busy)
for($i=0;$i<10000000;$i++) {
}
$data = getrusage();
echo "User time: ".($data['ru_utime.tv_sec'] + $data['ru_utime.tv_usec'] / 1000000);
echo "System time: ".($data['ru_stime.tv_sec'] + $data['ru_stime.tv_usec'] / 1000000);
/* 输出
User time: 1.424592
System time: 0.004204
*/[/code]
这花了大约14秒的CPU时间,几乎所有的都是用户的时间,因为没有系统调用。
系统时间是CPU花费在系统调用上的上执行内核指令的时间。下面是一个例子:
[code]$start = microtime(true);
// keep calling microtime for about 3 seconds
while(microtime(true) - $start < 3) {
}
$data = getrusage();
echo "User time: ".($data['ru_utime.tv_sec'] + $data['ru_utime.tv_usec'] / 1000000);
echo "System time: ".($data['ru_stime.tv_sec'] + $data['ru_stime.tv_usec'] / 1000000);
/* prints
User time: 1.088171
System time: 1.675315
*/
我们可以看到上面这个例子更耗CPU
5、系统常量
PHP系统常量可以让你得到当前的行号 (LINE),文件 (FILE),目录 (DIR),函数名 (FUNCTION),类名(CLASS),方法名(METHOD) 和名字空间 (NAMESPACE),很像C语言。
我们可以以为这些东西主要是用于调试,当也不一定,比如我们可以在include其它文件的时候使用 FILE (当然,你也可以在 PHP 5.3以后使用 DIR ),下面是一个例子。
// this is relative to the loaded script's path
// it may cause problems when running scripts from different directories
require_once('config/database.php');
// this is always relative to this file's path
// no matter where it was included from
require_once(dirname(__FILE__) . '/config/database.php');[/code]
下面是使用 __LINE__ 来输出一些debug的信息,这样有助于你调试程序:
[code]// some code
// ...
my_debug("some debug message", __LINE__);
/* 输出
Line 4: some debug message
*/
// some more code
// ...
my_debug("another debug message", __LINE__);
/* 输出
Line 11: another debug message
*/
function my_debug($msg, $line) {
echo "Line $line: $msg\n";
}
6、生成唯一的ID
有很多人使用md5来生成一个唯一的ID,如下所示:
echo md5(time() . mt_rand(1,1000000));
其实,PHP中有一个叫uniqid的函数是专门用来干这个的:
// generate unique string
echo uniqid();
/* 输出
4bd67c947233e
*/
// generate another unique string
echo uniqid();
/* 输出
4bd67c9472340
*/
可能你会注意到生成出来的ID前几位是一样的,这是因为生成器依赖于系统的时间,这其实是一个非常不错的功能,因为你是很容易为你的这些ID排序的。这点MD5是做不到的。
你还可以加上前缀避免重名:
// 前缀
echo uniqid('foo_');
/* 输出
foo_4bd67d6cd8b8f
*/
// 有更多的熵
echo uniqid('',true);
/* 输出
4bd67d6cd8b926.12135106
*/
// 都有
echo uniqid('bar_',true);
/* 输出
bar_4bd67da367b650.43684647
*/
而且,生成出来的ID会比MD5生成的要短,这会让你节省很多空间。
7. 数据序列化
你是否会把一个比较复杂的数据结构存到数据库或是文件中?你并不需要自己去写自己的算法。PHP早已为你做好了,其提供了两个函数: serialize和unserialize
// 一个复杂的数组
$myvar = array(
'hello',
42,
array(1,'two'),
'apple'
);
// 序列化
$string = serialize($myvar);
echo $string;
/* 输出
a:4:{i:0;s:5:"hello";i:1;i:42;i:2;a:2:{i:0;i:1;i:1;s:3:"two";}i:3;s:5:"apple";}
*/
// 反序例化
$newvar = unserialize($string);
print_r($newvar);
/* 输出
Array
(
[0] => hello
[1] => 42
[2] => Array
(
[0] => 1
[1] => two
)
[3] => apple
)
*/
这是PHP的原生函数,然而在今天JSON越来越流行,所以在PHP5.2以后,PHP开始支持JSON,你可以使用 json_encode() 和 json_decode() 函数
// a complex array
$myvar = array(
'hello',
42,
array(1,'two'),
'apple'
);
// convert to a string
$string = json_encode($myvar);
echo $string;
/* prints
["hello",42,[1,"two"],"apple"]
*/
// you can reproduce the original variable
$newvar = json_decode($string);
print_r($newvar);
/* prints
Array
(
[0] => hello
[1] => 42
[2] => Array
(
[0] => 1
[1] => two
)
[3] => apple
)
*/
这看起来更为紧凑一些了,而且还兼容于Javascript和其它语言。但是对于一些非常复杂的数据结构,可能会造成数据丢失。
8、字符串压缩
当我们说到压缩,我们可能会想到文件压缩,其实,字符串也是可以压缩的。PHP提供了 gzcompress和gzuncompress
$string = "Lorem ipsum dolor sit amet, consectetur
adipiscing elit. Nunc ut elit id mi ultricies
adipiscing. Nulla facilisi. Praesent pulvinar,
sapien vel feugiat vestibulum, nulla dui pretium orci,
non ultricies elit lacus quis ante. Lorem ipsum dolor
sit amet, consectetur adipiscing elit. Aliquam
pretium ullamcorper urna quis iaculis. Etiam ac massa
sed turpis tempor luctus. Curabitur sed nibh eu elit
mollis congue. Praesent ipsum diam, consectetur vitae
ornare a, aliquam a nunc. In id magna pellentesque
tellus posuere adipiscing. Sed non mi metus, at lacinia
augue. Sed magna nisi, ornare in mollis in, mollis
sed nunc. Etiam at justo in leo congue mollis.
Nullam in neque eget metus hendrerit scelerisque
eu non enim. Ut malesuada lacus eu nulla bibendum
id euismod urna sodales. ";
$compressed = gzcompress($string);
echo "Original size: ". strlen($string)."\n";
/* 输出原始大小
Original size: 800
*/
echo "Compressed size: ". strlen($compressed)."\n";
/* 输出压缩后的大小
Compressed size: 418
*/
// 解压缩
$original = gzuncompress($compressed);
几乎有50% 压缩比率。同时,你还可以使用gzencode和gzdecode函数来压缩,只不过其用了不同的压缩算法。
9、注册停止函数
有一个函数叫做register_shutdown_function,可以让你在整个脚本停止前运行代码。脚本停止前运行是指在执行完所有PHP语句后再调用函数,不要理解成客户端关闭流浏览器页面时调用函数。
可以这样理解调用条件:
- 当页面被用户强制停止时
- 当程序代码运行超时时
- 当PHP代码执行完成时
让我们看下面的两个示例加以理解:
function shutdown() {
global $salary;
$salary ? die('HeHe!') : die('No salary!');
}
register_shutdown_function('shutdown');
$salary = false;
exit; //手动停止代码往下执行。代码执行到这里时,将调用 shutdown 函数
$salary = true;[/code]
[code]function shutdown() {
global $salary;
$salary ? die('HeHe!') : die('No salary!');
}
register_shutdown_function('shutdown');
$salary = false;
$theobj = 1;
$theobj = new Salary(); // 类不存在,发生致命错误,代码停止执行。此时将调用 shutdown 函数;
$salary = true;
文件哪里存?当然选网盘,永久免费、容量够大、速度快。
不过下载是个问题,网盘一盘不提供直链,只能进入分享页手动下载,虽然下载后能看到直链,但这个直链是有时间限制的,也就是说那是临时的。
需求来了,当我们把文件存储到网盘后,并不希望用户跑到网盘去下载,而是点击链接就直接下载
下面提供一个封装好的百度网盘真实下载地址提取函数,有空再去研究研究微云的
function baiduPan($url) {
if (strpos($url, 'pan.baidu.com') === false) return false;
$ch = curl_init();
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_URL, $url);
$html = curl_exec($ch);
if (preg_match('/bdstoken="(.*?)".*?fsId="(.*?)".*?share_uk="(.*?)".*?share_id="(.*?)"/i', $html, $matches)) {
$proxyUrl = sprintf('http://pan.baidu.com/share/download?bdstoken=%s&uk=%s&shareid=%s&fid_list=%%5B%s%%5D', $matches[1], $matches[3], $matches[4], $matches[2]);
curl_setopt($ch, CURLOPT_URL, $proxyUrl);
$proxyHtml = curl_exec($ch);
$jsonObj = json_decode($proxyHtml, true);
$downloadButtonUrl = $jsonObj['dlink'];
$downloadButtonUrl = str_replace("\\\\/", "/", $downloadButtonUrl);
curl_setopt($ch, CURLOPT_URL, $downloadButtonUrl);
curl_setopt($ch, CURLOPT_VERBOSE, 1);
curl_setopt($ch, CURLOPT_HEADER, 1);
$result = curl_exec($ch);
list($header, $body) = explode("\r\n\r\n", $result, 2);
if (preg_match('/Location: (.*?)(\r?\n)/is', $header, $matches)) {
return $matches[1];
}
}
return false;
}
$testurl = 'http://pan.baidu.com/share/link?shareid=3142223074&uk=1864945200';
$downurl = baiduPan($testurl);
//这个就是文件的真实下载地址,可以用浏览器或者下载工具试试
echo $downurl;
规则是活的,代码是死的,所以无法保证可以永久使用,如发现无法正常使用,那就是网盘规则变了,需要自行修改代码咯,就个人经验来看,百度网盘一般两到三个月会更新一次,不过变化不会太大。
通过本函数,可以计算出指定目录的所有文件个数,以及遍历所有的文件
/**
* @path 路径,支持相对和绝对
* @absolute 返回的文件数组,是否包含完整路径
*/
function get_files($path, $absolute=1) {
$files = array();
$_path = realpath($path);
if (!file_exists($_path)) return false;
if (is_dir($_path)) {
$list = scandir($_path);
foreach ($list as $v) {
if ($v == '.' || $v == '..') continue;
$_paths = $_path.'/'.$v;
if (is_dir($_paths)) {
//递归
$files = array_merge($files, get_files($_paths,$absolute));
} else {
$files[] = $absolute>0 ? $_paths : $v;
}
}
} else {
if (!is_file($_path)) return false;
$files[] = $_path;
}
return $files;
}
$a = get_files('./Caige/api');
$b = get_files('./Caige/api', 0);
echo '<pre>';
var_dump($a);
var_dump($b);
echo count($a).'<br />'.count($b);
很多时候,我们需要对请求来源进行区别处理,如主题模版、智能推广等等...
PHP作为作为后端语言,没办法像前端语言一样获取机器设备信息
下面这个函数,可以帮助你实现对手机用户的判断识别:
function ismobile() {
// 如果有HTTP_X_WAP_PROFILE则一定是移动设备
if (isset ($_SERVER['HTTP_X_WAP_PROFILE']))
return true;
//此条摘自TPM智能切换模板引擎,适合TPM开发
if(isset ($_SERVER['HTTP_CLIENT']) &&'PhoneClient'==$_SERVER['HTTP_CLIENT'])
return true;
//如果via信息含有wap则一定是移动设备,部分服务商会屏蔽该信息
if (isset ($_SERVER['HTTP_VIA']))
//找不到为flase,否则为true
return stristr($_SERVER['HTTP_VIA'], 'wap') ? true : false;
//判断手机发送的客户端标志,兼容性有待提高
if (isset ($_SERVER['HTTP_USER_AGENT'])) {
$clientkeywords = array(
'nokia','sony','ericsson','mot','samsung','htc','sgh','lg','sharp','sie-','philips','panasonic','alcatel','lenovo','iphone','ipod','blackberry','meizu','android','netfront','symbian','ucweb','windowsce','palm','operamini','operamobi','openwave','nexusone','cldc','midp','wap','mobile'
);
//从HTTP_USER_AGENT中查找手机浏览器的关键字
if (preg_match("/(" . implode('|', $clientkeywords) . ")/i", strtolower($_SERVER['HTTP_USER_AGENT']))) {
return true;
}
}
//协议法,因为有可能不准确,放到最后判断
if (isset ($_SERVER['HTTP_ACCEPT'])) {
// 如果只支持wml并且不支持html那一定是移动设备
// 如果支持wml和html但是wml在html之前则是移动设备
if ((strpos($_SERVER['HTTP_ACCEPT'], 'vnd.wap.wml') !== false) && (strpos($_SERVER['HTTP_ACCEPT'], 'text/html') === false || (strpos($_SERVER['HTTP_ACCEPT'], 'vnd.wap.wml') < strpos($_SERVER['HTTP_ACCEPT'], 'text/html')))) {
return true;
}
}
return false;
}
Return Top
|