一般的,一个看似很简单的页面,一次http请求后,到达服务端,穿过Cache层,落到后台后,实际可能会有很多很多的数据查询逻辑!而这些查询实际是不相互依赖的,也即可以同时查询。比如各种用户信息,用户的APP列表,每个APP对应的流量数据、消耗记录、服务状态,平台运行状态,消息通知,新闻资讯等等。
这篇文章主要介绍了数据查询层,如何把串行变并行,提高查询效率、提升应用性能。实现方式包括:mysqlnd异步查询,cURL并发请求,Swoole异步非阻塞!
PHP脚本是按文档流的形式来执行的,所以我们在编写PHP程序时,代码基本都是串行的,尤其是SQL,比如:

这种方式,是每次查询都需要等待结果返回之后再开始下一次的查询,
运行时间 = (第1次发送请求时间 + 0.01 + 第1次返回时间)+(第2次发送请求时间 + 0.05 + 第2次返回时间)+(第3次发送请求时间 + 0.03 + 第3次返回时间)
如果是并发查询,那么流程就成了:
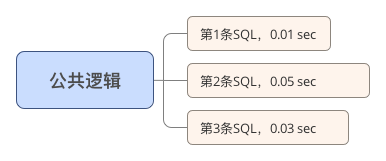
运行时间 = 发送请求时间 + 0.05 + 返回时间
显然,并发查询要比串行查询快!
那么PHP可以实现并发查询吗?答案是肯定的!
一、利用MySQL的异步查询功能
目前 MySQL 的异步查询,只在 MySQLi 扩展提供,查询方法分别是:
- 使用 MYSQLI_ASYNC 模式执行 mysqli::query
- 获取异步查询结果:mysqli::reap_async_query
需要注意的是,使用异步查询,需要使用 mysqlnd 作为PHP的MySQL数据库驱动,
mysqlnd(MySQL Native Driver) 是 Zend 公司开发的 MySQL 数据库驱动,采用PHP开源协议,用于代替旧版的由 MySQL AB公司(现在的Oracle)开发的 libmysql,PHP 5.3 及以上版本开始提供,PHP5.4 之后的版本 mysqlnd 为默认配置选项,
如果 PHP 小于 5.4,编译时需要指定编译参数:
--with-mysqli=mysqlnd --with-pdo-mysql=mysqlnd
MySQL异步查询示例脚本:
<?php
/**
* MySQL异步查询示例脚本:
* @filename p_async.php
* @url http://test.979137.com/ParallelSQL/p_async.php
*/
//期望结果集:获取以下用户的每个月每个APP的消费统计
$top = array('979137', '555555', '666666', '888888', '999999');
$ret = array_fill_keys($top, array());
//组织结构查询
$cmd = $resources = array();
$sql = "SELECT access_key,SUM(amount) sum_amount FROM consume_2016%s WHERE uid=%d AND product='SAE' GROUP BY access_key";
foreach($top as $uid) {
for($i = 1; $i <= 12; $i++) {
$ret[$uid][$i] = $tmp = array();
$tmp['uid'] = $uid;
$tmp['month'] = $i;
$tmp['resource'] = $resources[] = new \mysqli('localhost', 'root', '123456', 'sae', '3306');
$tmp['resource']->set_charset('utf8');
$tmp['resource']->query(sprintf($sql, sprintf('%02d', $i), $uid), MYSQLI_ASYNC);
$tag = spl_object_hash($tmp['resource']);
$cmd[$tag] = $tmp;
}
}
$total = $query_times = count($resources);
//获取结果
do {
$read = $error = $reject = $resources;
//等待查询结束
if (!\mysqli::poll($read, $error, $reject, 1)) {
continue;
}
//批量获取结果
foreach($read as $resource) {
$result = $resource->reap_async_query();
if ($result) {
$tag = spl_object_hash($resource);
$uid = $cmd[$tag]['uid'];
$month = $cmd[$tag]['month'];
while(($row = $result->fetch_assoc()) != false) {
$ret[$uid][$month][$row['access_key']] = $row['sum_amount'];
}
$result->free();
$total--;
} else die('MySQLi error: '.$resource->error);
}
} while ($total > 0);
var_dump($ret);
二、cURL实现并发请求
先解释下 cURL 和 SQL 怎么就扯上关系了呢!
我们知道在很多系统架构里,PHP是不会直接操作DB的,而是 RESTful 架构,这时候所有操作都接口化了,
这时上述所讲的 SQL 就演变成 接口调用 了,
因为 API,所以 cURL!
以下是PHP中cURL多线程相关函数:
curl_multi_add_handle — 向curl批处理会话中添加单独的curl句柄
curl_multi_close — 关闭一组cURL句柄
curl_multi_exec — 运行当前 cURL 句柄的子连接
curl_multi_getcontent — 如果设置了CURLOPT_RETURNTRANSFER,则返回获取的输出的文本流
curl_multi_info_read — 获取当前解析的cURL的相关传输信息
curl_multi_init — 返回一个新cURL批处理句柄
curl_multi_remove_handle — 移除curl批处理句柄资源中的某个句柄资源
curl_multi_select — 等待所有cURL批处理中的活动连接
curl_multi_setopt — 为 cURL 并行处理设置一个选项
curl_multi_strerror — 返回描述错误码的字符串文本
我们可以利用这些多线程函数,实现 cURL 并发请求,从而实现并发 SQL!
cURL并发请求,服务端接口示例脚本:
<?php
/**
* cURL并发请求,服务端接口示例脚本
* @filename consume.php
* @url http://test.979137.com/ParallelSQL/consume.php
*/
$resource = new \mysqli('localhost', 'root', '123456', 'sae', '3306');
$resource->set_charset('utf8');
$sql = "SELECT access_key,SUM(amount) sum_amount FROM consume_%d WHERE uid=%d AND product='%s' GROUP BY access_key";
$sql = sprintf($sql, $_GET['ym'], $_GET['uid'], $_GET['product']);
$res = $resource->query($sql);
$out['code'] = $resource->errno;
$out['message'] = $resource->error;
$data = array();
if (is_object($res)) {
while(($row = $res->fetch_assoc()) != false) {
$data[$row['access_key']] = $row['sum_amount'];
}
}
$out['data'] = $data;
header('Content-Type: application/json; charset=utf-8');
echo json_encode($out);
cURL并发请求,客户端调用示例脚本:
<?php
/**
* cURL并发请求,客户端调用示例脚本
* @filename p_curl.php
* @url http://test.979137.com/ParallelSQL/p_curl.php
*/
//期望结果集:获取以下用户的每个月每个APP的消费统计
$top = array('979137', '555555', '666666', '888888', '999999');
$ret = array_fill_keys($top, array());
$mch = curl_multi_init();
$opt[CURLOPT_HEADER] = 0;
$opt[CURLOPT_CONNECTTIMEOUT] = 60;
$opt[CURLOPT_RETURNTRANSFER] = true;
$opt[CURLOPT_HTTPHEADER] = array('Host: api.979137.com');
//生成句柄并加入到批处理
$cmd = array();
foreach($top as $uid) {
for($i = 1; $i <= 12; $i++) {
$ret[$uid][$i] = $tmp = array();
$tmp['url'] = sprintf('http://127.0.0.1/ParallelSQL/consume.php?ym=2016%02d&uid=%d&product=SAE', $i, $uid);
$tmp['uid'] = $uid;
$tmp['month'] = $i;
$tmp['resource'] = curl_init($tmp['url']);
curl_setopt_array($tmp['resource'], $opt);
curl_multi_add_handle($mch, $tmp['resource']);
$cmd[] = $tmp;
}
}
//并发执行,直到全部结束
do {
curl_multi_exec($mch, $active);
} while ($active > 0);
//获取全部结果
foreach($cmd as $c) {
$res = curl_multi_getcontent($c['resource']);
$http_code = curl_getinfo($c['resource'], CURLINFO_HTTP_CODE);
if ($res === false || $http_code != 200) {
die(curl_error($c['resource']));
}
$res = json_decode($res, true);
$res['code'] && die($res['message']);
$ret[$c['uid']][$c['month']] = $res['data'];
}
curl_multi_close($mch);
var_dump($ret);
查询效率对比
1、数据表机构:
CREATE TABLE `consume_201612` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`uid` int(10) unsigned NOT NULL,
`product` enum('UID','SAE','SC2','SCE','SEM','SCS','SLS') NOT NULL DEFAULT 'SAE',
`access_key` varchar(255) NOT NULL,
`service_code` varchar(255) NOT NULL,
`amount` int(10) unsigned NOT NULL,
`remark` varchar(255) NOT NULL,
`data` text NOT NULL,
`times` int(10) unsigned NOT NULL,
PRIMARY KEY (`id`),
KEY `uid_pa` (`uid`,`product`,`access_key`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2、数据量:总共分12张表,每张表的数量在 500万~1100万 之间,全量数据在1亿以上
3、MySQL异步查询结果:
$ mysql.server restart
$ php p_async.php
Query times: 60
Run time: 2.4453s
(CPU)User time: 0.087966s
(CPU)System time: 0.117625s
4、cURL并发请求查询结果
$ mysql.server restart
$ php p_curl.php
Query times: 60
Run time: 2.173035s
(CPU)User time: 0.40652s
(CPU)System time: 0.869902s
5、普通串行查询结果
$ mysql.server restart
$ php p_sync.php
Query times: 60
Run time: 20.485623s
(CPU)User time: 0.083185s
(CPU)System time: 0.036566s
Memory usage: 304.72kb
并发执行时,我们可以在 MySQL 服务器看到所有的正在执行的SQL:
总结
1、在并发查询下,查询效率提高了近10倍
2、使用 MySQL 异步查询,因为需要给所有查询都创建一个新的连接,而 MySQL 服务端会为每个连接创建一个单独的线程进行处理,如果创建的线程数过多,会给系统造成负担,请谨慎使用
3、使用 cURL 并发请求后端接口时,CPU负载明显上升,所以并发请求后端接口,一定程度上会增加后端压力,这和前端大流量下的高并发原理是一样的
4、使用 cURL 并发请求,还需要考虑一个网络延时的问题,网络延时越小,查询效率提升越明显。如果你是想代替类方法或函数调用,在条件允许的情况,建议直接连接服务器本机即127.0.0.1
5、在并发请求下,因为需要一次性接收全部返回结果,所以会占用更多的内存资源
需要说明的是,在实际应用中 cURL 的并发请求,一般不只单用于数据查询,而是为了完成更多的后台业务逻辑,
所以,在服务器负载能力允许的情况下,推荐使用 cURL 并行转发的形式,提升前端响应速度!
最后说一下 Swoole,
Swoole 是 PHP 的异步、并行、高性能网络通信引擎,使用纯C语言编写,提供了PHP语言的异步多线程服务器,异步TCP/UDP网络客户端,异步MySQL,异步Redis,数据库连接池,AsyncTask,消息队列,毫秒定时器,异步文件读写,异步DNS查询!
其中的异步MySQL,其原理是通过 MYSQLI_ASYNC 模式查询,然后获取 mysql 连接的 socket,加入到 epoll 时间循环中,当数据库返回结果时会回调指定函数。
这个过程是完全异步非阻塞的,不浪费CPU,具体实现方式这里不再详细介绍!
