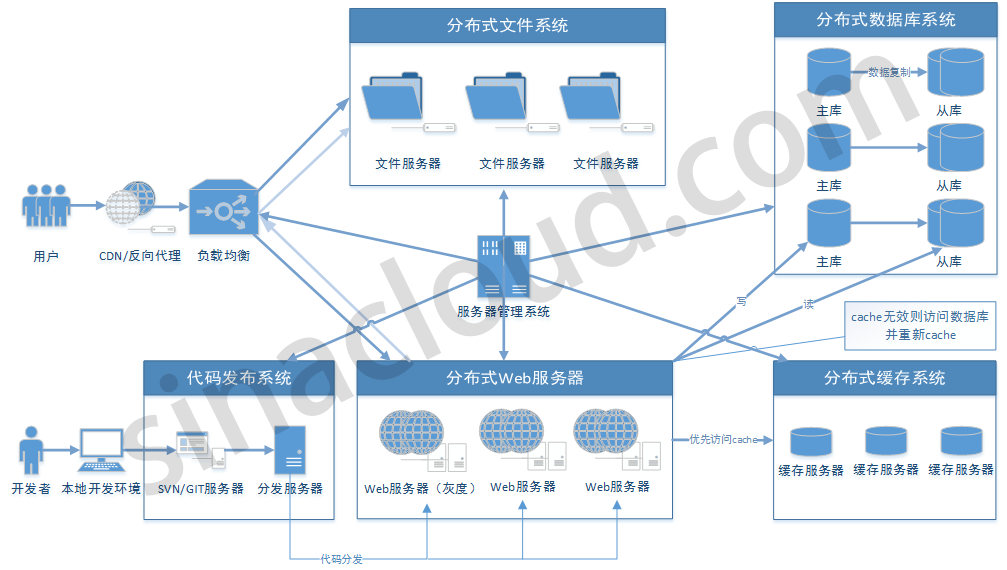
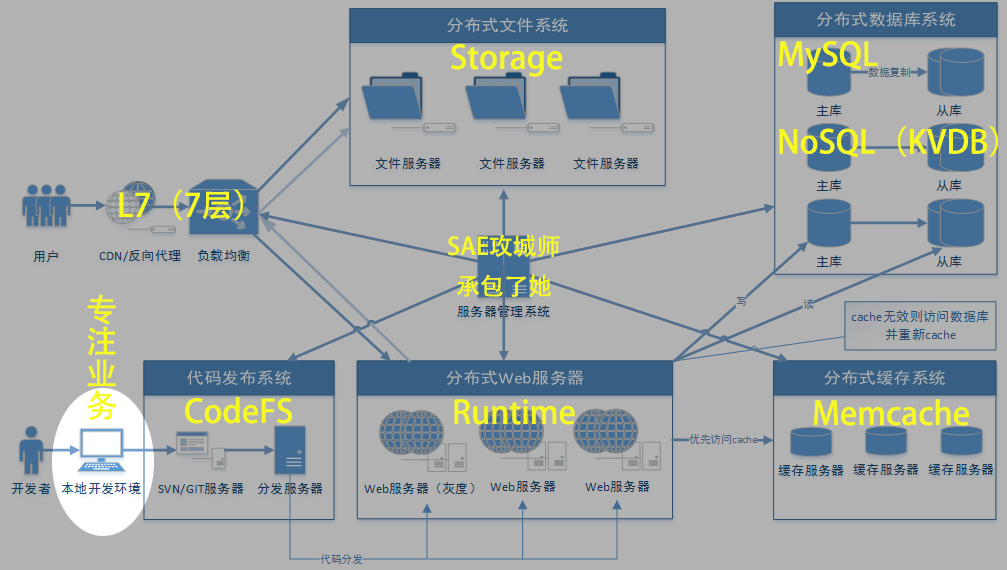
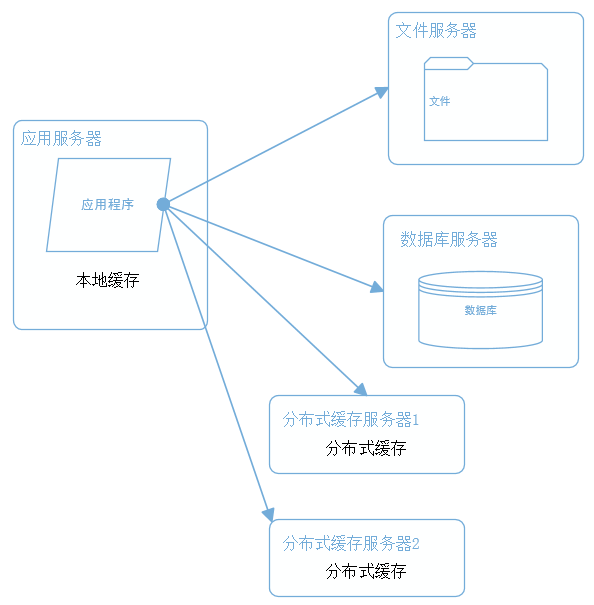
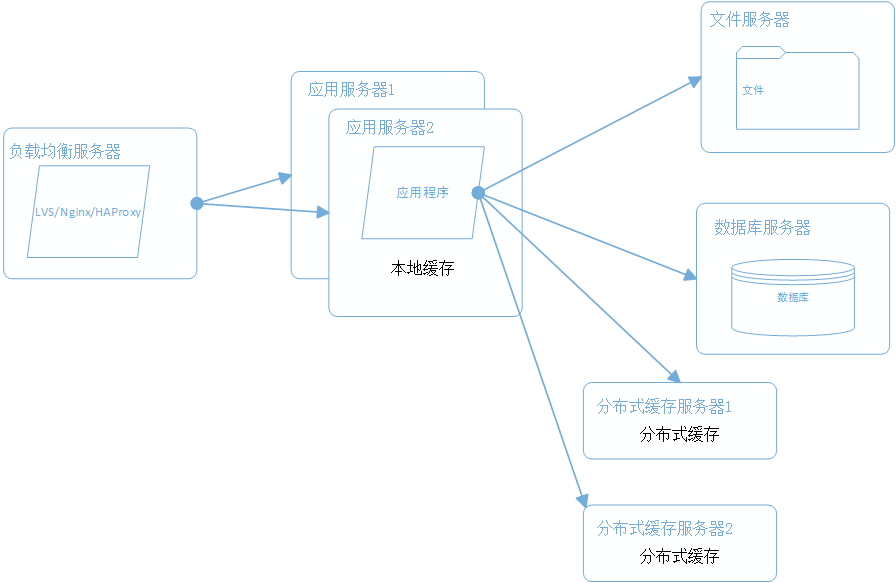
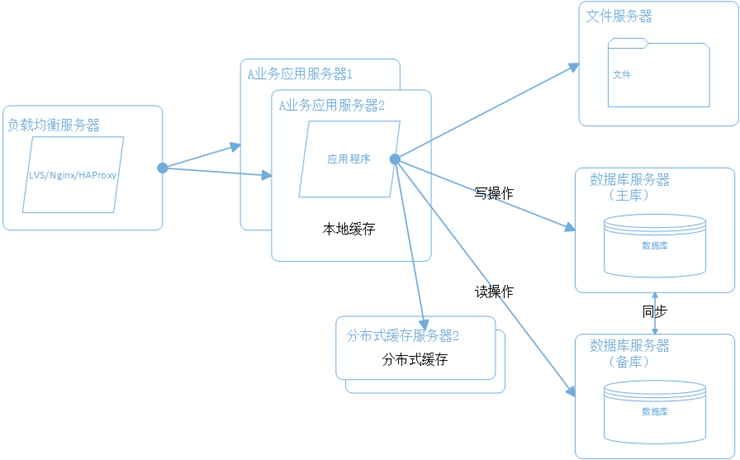
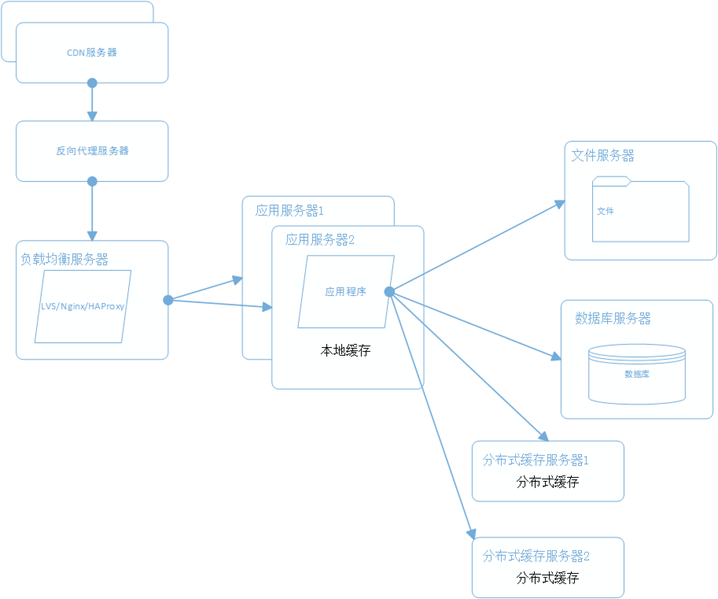
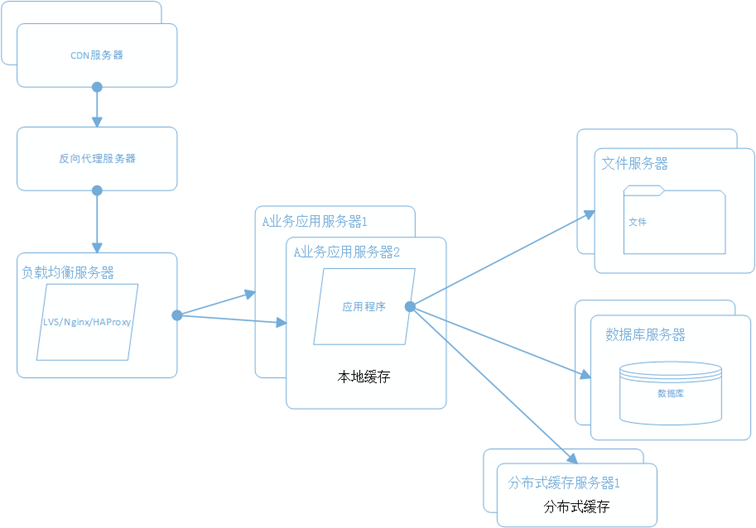
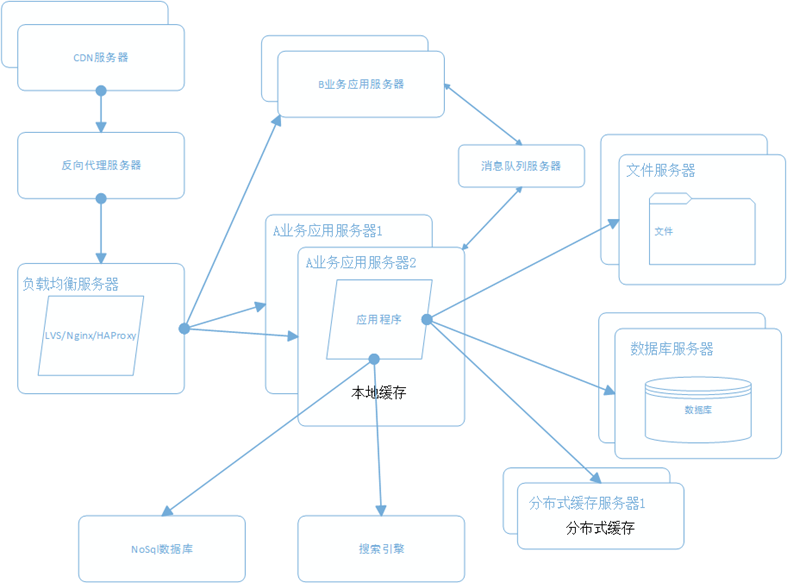
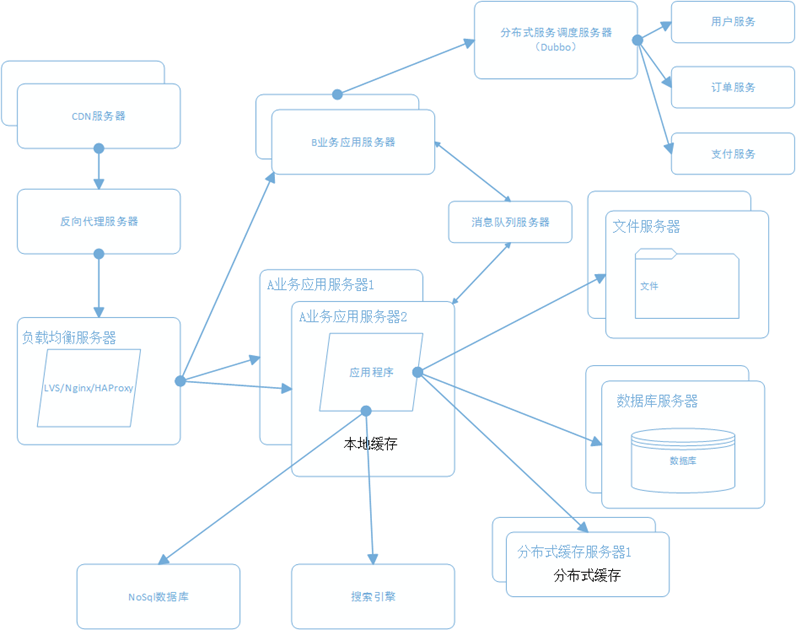
新浪云SAE云空间在分布式基础上,几乎实现了普通虚拟主机全兼容的环境,但还是有一点点区别,比如URL Rewrite,新浪云空间实现URL Rewrite是通过在根目录编写一个 .appconfig 来实现的,同时在规则上也有一些区别
官方提供了一个原生 .htaccess 到 .appconfig 的转换工具:
http://htaccess.applinzi.com
我试了下 Discuz 的 Rewrite,转换后,发现没什么软用
RewriteEngine On
RewriteBase /
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^/data1/www/htdocs/711//1/topic-(.+)\.html$ portal.php?mod=topic&topic=$1&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^/data1/www/htdocs/711//1/article-([0-9]+)-([0-9]+)\.html$ portal.php?mod=view&aid=$1&page=$2&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^/data1/www/htdocs/711//1/forum-(\w+)-([0-9]+)\.html$ forum.php?mod=forumdisplay&fid=$1&page=$2&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^/data1/www/htdocs/711//1/thread-([0-9]+)-([0-9]+)-([0-9]+)\.html$ forum.php?mod=viewthread&tid=$1&extra=page\%3D$3&page=$2&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^/data1/www/htdocs/711//1/group-([0-9]+)-([0-9]+)\.html$ forum.php?mod=group&fid=$1&page=$2&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^/data1/www/htdocs/711//1/space-(username|uid)-(.+)\.html$ home.php?mod=space&$1=$2&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^/data1/www/htdocs/711//1/blog-([0-9]+)-([0-9]+)\.html$ home.php?mod=space&uid=$1&do=blog&id=$2&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^/data1/www/htdocs/711//1/archiver/(fid|tid)-([0-9]+)\.html$ archiver/index.php?action=$1&value=$2&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^/data1/www/htdocs/711//1/([a-z]+[a-z0-9_]*)-([a-z0-9_\-]+)\.html$ plugin.php?id=$1:$2&%1[
下面是我改写的、亲测有效的 Rewrite 规则:
RewriteEngine On
RewriteBase /
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/topic-(.+)\.html$ portal.php?mod=topic&topic=$2&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/article-([0-9]+)-([0-9]+)\.html$ portal.php?mod=view&aid=$2&page=$3&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/forum-(\w+)-([0-9]+)\.html$ forum.php?mod=forumdisplay&fid=$2&page=$3&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/thread-([0-9]+)-([0-9]+)-([0-9]+)\.html$ forum.php?mod=viewthread&tid=$2&extra=page\%3D$4&page=$3&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/group-([0-9]+)-([0-9]+)\.html$ forum.php?mod=group&fid=$2&page=$3&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/space-(username|uid)-(.+)\.html$ home.php?mod=space&$2=$3&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/blog-([0-9]+)-([0-9]+)\.html$ home.php?mod=space&uid=$2&do=blog&id=$3&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/(fid|tid)-([0-9]+)\.html$ index.php?action=$2&value=$3&%1
RewriteCond %{QUERY_STRING} ^(.*)$
RewriteRule ^(.*)/([a-z]+[a-z0-9_]*)-([a-z0-9_\-]+)\.html$ plugin.php?id=$2:$3&%1