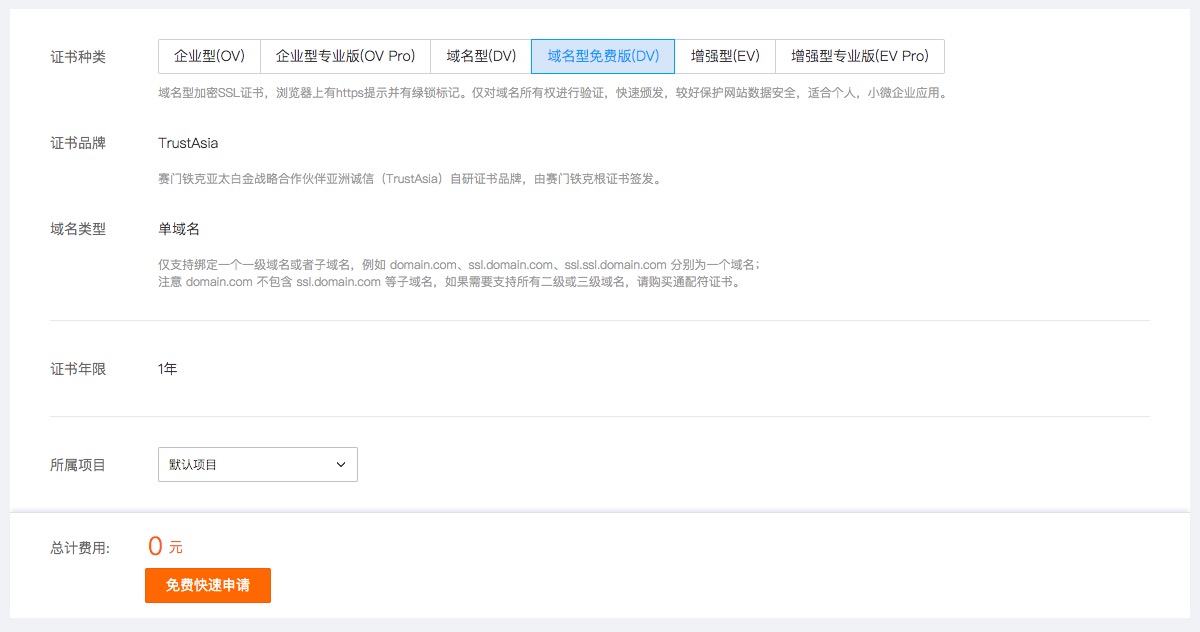
一般大型Web应用是指具有大流量、高并发、海量数据等特征的Web应用,
支撑此类应用,必需要一个安全、高可靠、可扩展、易维护的动态平台,才能保证应用的平稳运行。
下面我们先来聊聊,如何架构一个支撑大型Web应用的动态平台?
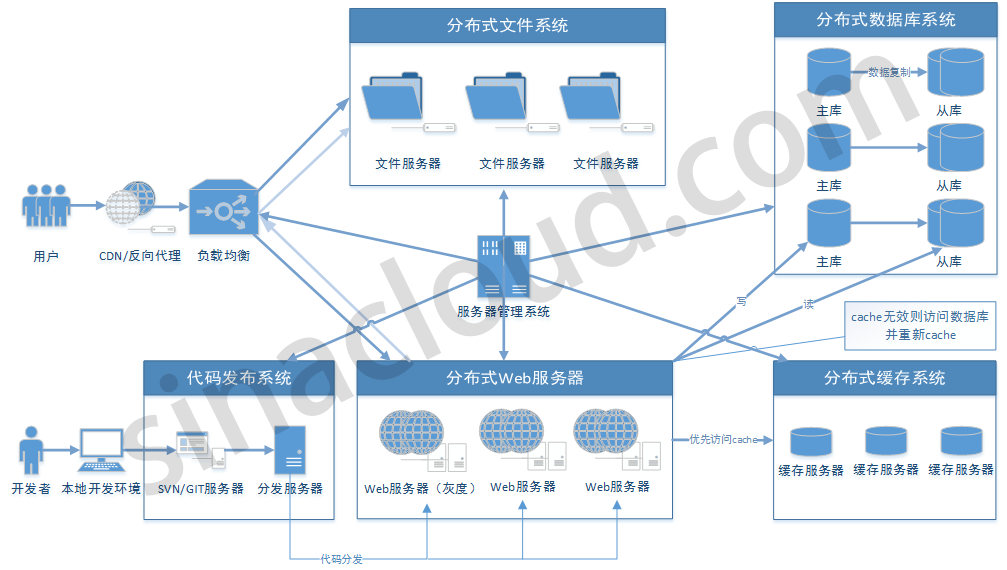
上图是较多大型应用采用的架构模式(实际应用中,会随着业务和需求的复杂程度,而出现更多更复杂的多层架构)
1、分布式Web服务器
如前言所述,大型应用,具有大流量、高并发的特征,一台服务器,显然无法满足需求。
以一个日均8亿PV的网站为例,根据PV我们计算出每秒的并发为1万,并发峰值是3.7万(每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间),如果要保证100QPS,则至少需要400台服务器一起分担压力。
另外,大型应用业务普遍比较复杂,业务拆分是很常见的架构模式,如微博平台针对用户的行为、关系、设置等从技术架构中进行了业务拆分。
2、负载均衡系统
负载均衡和分布式Web服务器可以说是“连体婴儿”,负载均衡系统是所有请求的入口,请求到达时,根据分发策略将请求分发到健康的Web服务器节点,从而实现对请求的合理调度。
负载均衡分为硬件和软件两种。硬件负载均衡效率高,但是价格贵。软件负载均衡系统价格较低或者免费,但效率较硬件负载均衡系统低,常见的如LVS、Nginx,软硬负载均衡系统并用也是常见的均衡方式。
3、CDN、反向代理
大型应用普遍用户量都非常庞大,遍布全国各地,甚至全球,并且处于不同的网络环境。所以需要CDN,去解决跨地区、跨运营商的访问速度问题。反向代理,则是部署在应用所在机房,请求到达时,首先访问反向代理服务器,反向代理服务器将缓存的数据返回给用户,如果没有缓存数据才会继续走应用服务器获取,减少获取数据的成本。反向代理有Squid、Nginx等
4、分布式数据库系统
很多大型应用都会面临一个数据库性能瓶颈问题,海量数据如何存储?高并发情况下如果保证数据库负载问题?复杂业务逻辑如何保证数据的一致性、安全性?大流量面前如果保证查询效率?
一个大型应用,必然需要一个高可靠的、可以提供大规模并发处理的数据库体系,如此才能保证整个应用的高可靠性。
一般数据库系统都会同时使用关系型(如MySQL)数据库和非关系型(即NoSQL,如MongoDB、Redis)数据库,以满足不同的业务场景。
在分布式部署的基础上,还会采用主从架构、读写分离,主库抗写压力,通过从库来分担读压力。
5、分布式缓存系统
在海量数据、大流量、高并发面前,光有高可靠的分布式数据库系统,是远远不够的!
缓存技术是关键,在大型Web应用中使用最多且效率最高的是内存缓存,最常用的内存缓存工具是Memcached。
一个好的缓存机制,可以提高访问效率、提高服务器吞吐能力、减轻数据库系统和文件系统的访问压力。
分布式缓存系统,则可以避免单点故障,提高性能,提供高可靠性和可扩展性,巨大容量的缓存池,也可以将发生宕机时缓存的穿透率维持在一个很低的水平。
6、分布式文件系统
大规模存储,也是大型应用一大特征,如图片、视频、音乐、压缩包等等。
因此高性能的分布式存储系统对于大型应用来说是非常重要的一环。
7、代码发布系统
从 本地开发 到 生产环境(测试),再到 灰度发布,再到 全网发布,
为了满足分布式环境下程序代码的批量分发和更新,大型应用都需要一个代码发布系统和机制。
8、分布式服务器管理系统
文章开头,我们提出一个 “易维护” 概念,何谓 “易维护”?
就是能够集中式的、分组的、批量的、自动化的对所有服务器进行管理,能够批量化的执行计划任务。
常见的集中配置管理系统和软件有:puppet、Cfengine
OK!到此,我们大概地全面描述了一个支撑大型Web应用的动态平台架构。
那么问题来了,架构一个这样的动态平台,需要多少人力成本?周期?IT成本?稳定性?安全性?可靠性?
你也许看到过诸如 “如何理解云计算中的IaaS、PaaS和SaaS”、“PaaS和IaaS的区别”、“为什么选择PaaS” 等等之类的文章。
现在请先忘了那些乱七八糟的概念,这一次,我们站在实际用例的角度,看看国内领先的 PaaS 云平台SAE是如何优雅的帮你解决以上问题的!
一张图告诉你,在SAE架构一个大型Web应用到底有多简单!
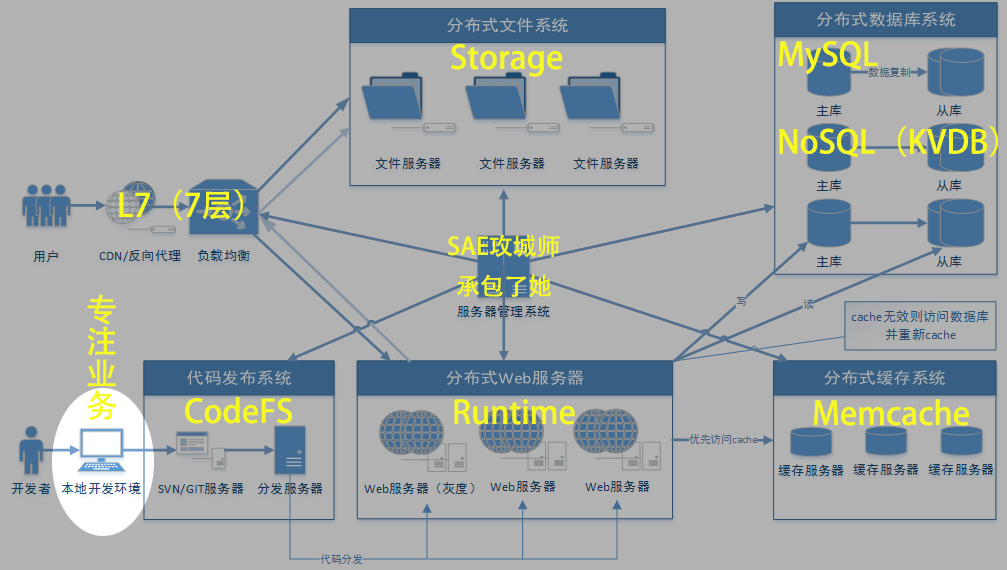
如你所见,SAE用成熟稳定的技术,帮您解决了所有问题,开发者只需专注于业务本身(写自己的代码,让别人加班去吧!)
1、分布式Web服务器
分布式部署是PaaS的天然特性,自然也是SAE的一大特性,在SAE的所有应用均是分布式部署,相当于每台Web服务器上都有代码,避开单点故障问题,稳定性不言而喻。
SAE的Web服务器,相当于纯粹的代码运行环境,我们先且称之为SAE Runtime吧!
SAE通过沙箱机制,将代码、数据、连接数、内存、CPU进行了安全隔离,保证了应用的绝对安全性。
看完这篇文章,你会发现,其实SAE全平台的Web服务都是分布式的。
2、负载均衡系统
SAE的Web服务器采用分布式部署的架构,这就需要均衡每一台服务器的负载,从而保证每一个请求的访问速度。
SAE通过7层(至于为什么叫7层,可能是因为它工作在OSI 7层网络模型的第7层应用层吧)经分析后转发到负载相对较小的Web服务器上。
3、CDN、反向代理
SAE的负载均衡服务器部署在电信机房,为了保证跨运营商访问速度,SAE在各大运营商的机房都有代理,代理通过专线和电信机房连接。
SAE拥有覆盖全国各大城市的多路(电信、联通、移动、教育)骨干网络CDN节点,用户只需简单的开启操作,就能使用高质量的CDN服务。
4、分布式数据库系统
SAE提供了MySQL、NoSQL(KVDB)两种分布式数据库服务,
SAE每组MySQL都采用 一主多从加一备份 的设计,充分保证了数据库的性能,以及数据的可靠性。
KVDB是SAE开发的分布式key-value数据存储服务,用来支持公有云计算平台上的海量key-value存储。KVDB支持的存储容量很大,对每个用户支持100G的存储空间,可支持1,000,000,000条记录。
KVDB是高性能高可靠存储,读写可达10W QPS。KVDB采用一主多从的分布式架构, SAE提供热备和定期冷备,发生宕机时,会自动切换到健康的DB上。
5、分布式缓存系统
SAE Memcache,是SAE为开发者提供分布式缓存服务。SAE Memcache采用企业级规模的缓存池。巨大容量的缓存池,将发生宕机时缓存的穿透率维持在一个很低的水平。同时支持无缝扩容,domain等概念。较传统Memcache更加稳定、可靠、高效。
6、分布式文件系统
Storage是 SAE 利用自身在分布式以及网络技术方面的优势为开发者提供的安全、高效的分布式对象存储服务,支持文本、多媒体、二进制等任何类型的数据的存储。开发者可通过客户端简单的完成文件的管理操作,SAE还提供了完整的 Storage API,以满足开发者的所有应用场景。
7、代码发布系统
在SAE,通过svn或git完成代码发布。代码提交后,SAE CodeFS会自动同步到所有Web服务器。
8、分布式服务器管理系统
......
(为什么是点点点??在SAE,你可以忘记这玩意了,因为在SAE是完全免运维的,开发者不需要管理自己的服务器,一切运维都交给了SAE!)
看到这里,你会发现,在SAE,其实每一个应用都是以大型应用的标准和规格运行着!
除此以外,SAE还提供了丰富的符合开发者实际业务场景的分布式Web服务,如:
DDoS防火墙/应用防火墙、FetchURL(分布式网页抓取服务)、Cron(分布式计划任务服务)、TaskQueue(分布式任务队列服务)、Channel(实时消息推送服务)、Push(手机通知推送服务,同时支持iOS、Android)等等,因为服务较多,为不使文章篇幅太长,就不一一介绍了!
如上,便是SAE(SinaAppEngine,http://sae.sina.com.cn)的魅力所在!